Asymmetric self-play for automatic goal discovery in robotic manipulation
Paper by OpenAI Robotics.
Cited as:
OpenAI et al. “Asymmetric self-play for automatic goal discovery in robotic manipulation” NeuriPS 2020 Deep Reinforcement Learning Workshop.
We train a single, goal-conditioned policy that can solve many robotic manipulation tasks, including tasks with previously unseen goals and objects. To do so, we rely on asymmetric self-play for goal discovery, where two agents, Alice and Bob, play a game. Alice is asked to propose challenging goals and Bob aims to solve them. We show that this method is able to discover highly diverse and complex goals without any human priors.
To the best of our knowledge, this is the first work that presents zero-shot generalization to many previously unseen tasks by training purely with asymmetric self-play.
Zero-shot Generalization
Our method scales, resulting in a single policy that can zero-shot generalize to many unseen hold-out tasks such as setting a table, stacking blocks, and solving simple puzzles. Example holdout tasks involving unseen objects and complex goal states.
The first two columns are vision observations captured by the front and wrist cameras, respectively. The third column is a goal image, fixed per goal solving trial.
Table Setting |
|
Ball Capture |
|
5-Piece Dominos |
|
3-Piece Rainbow |
|
Mini Chess |
|
Push 8 YCB Objects |
|
Stacking 3 Blocks |
|
Push 8 Blocks |
Novel Goals and Solutions
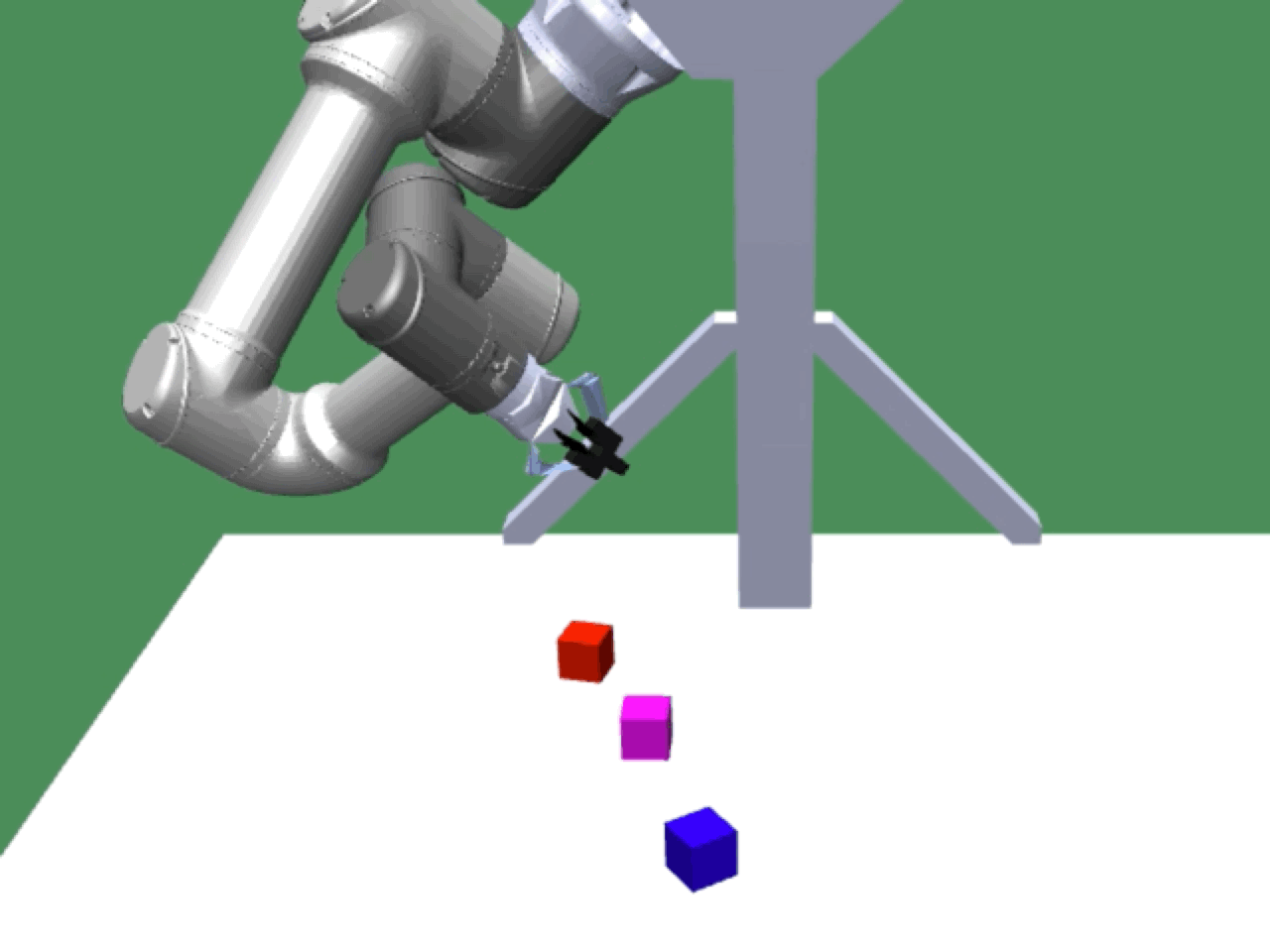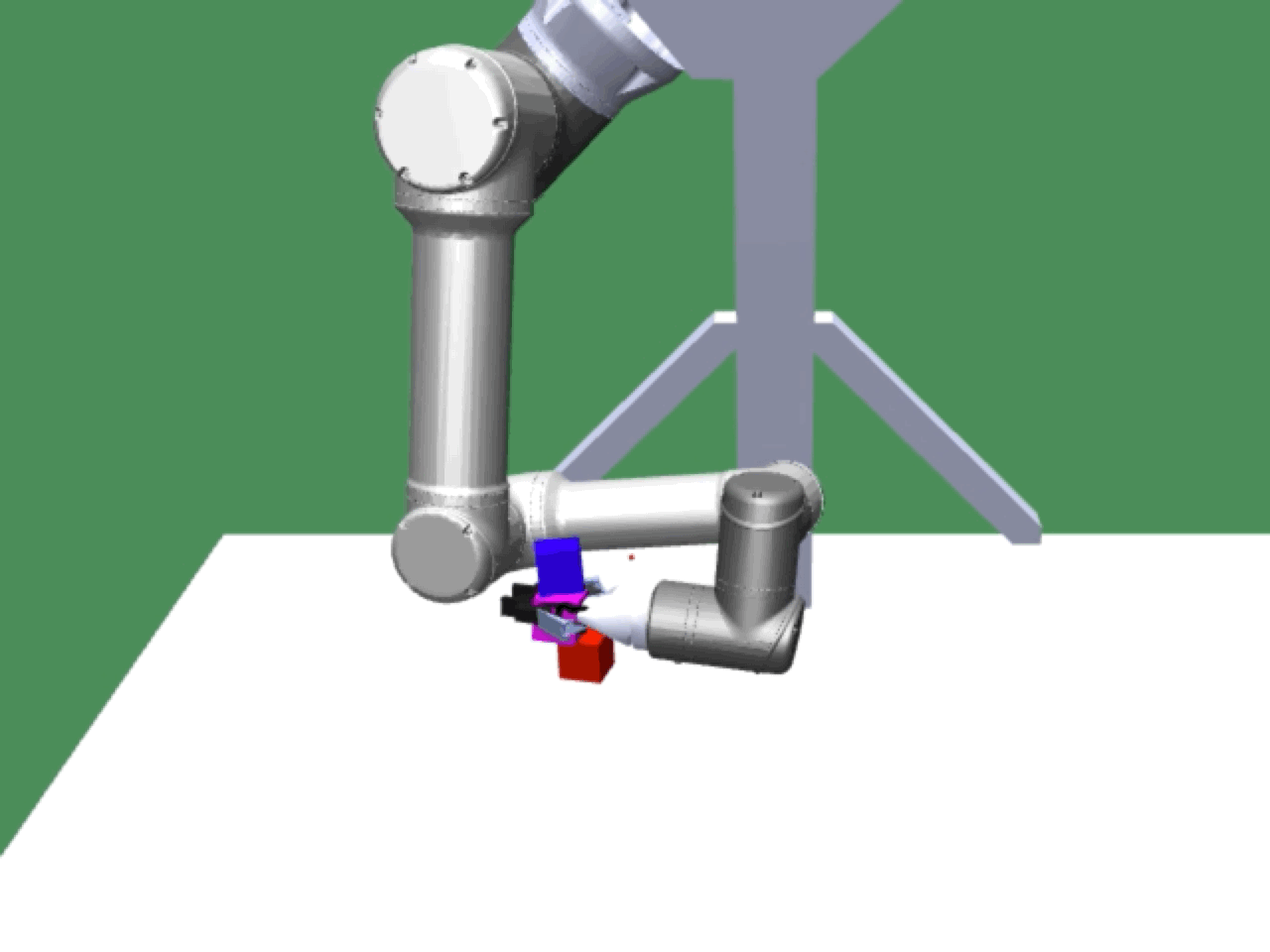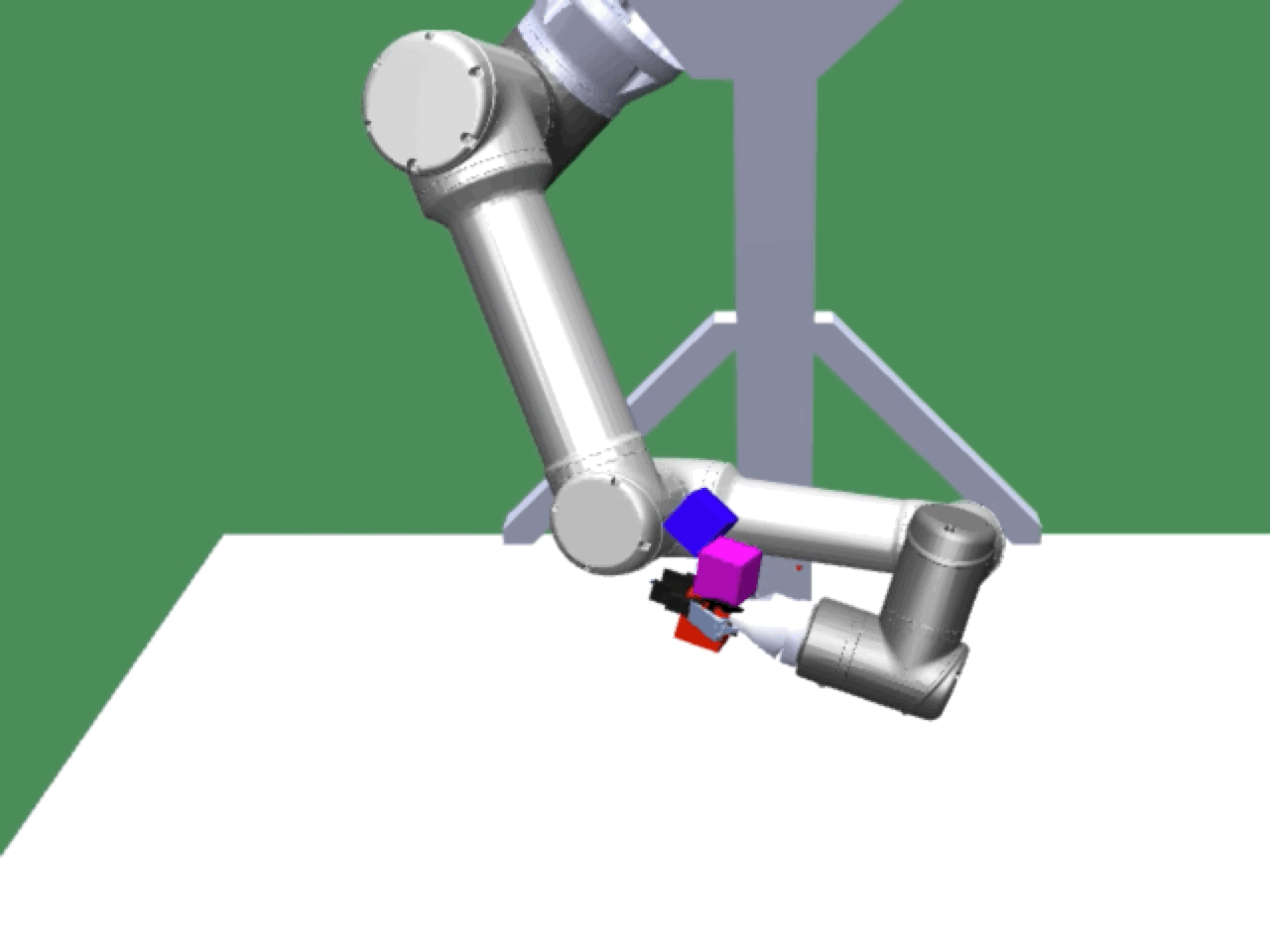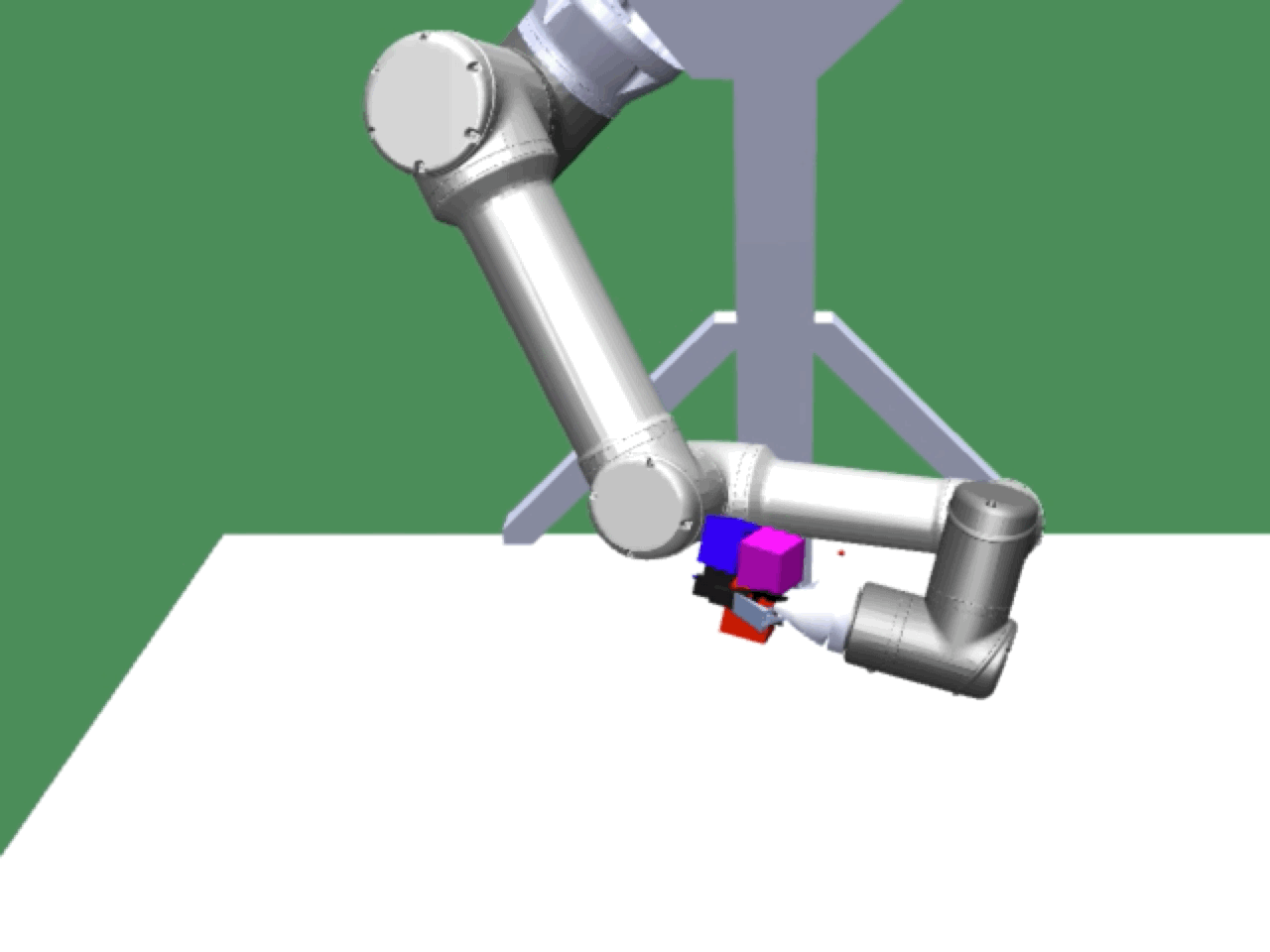
Alice discovers many goals that are not covered by our manually designed holdout tasks on blocks. Although it is a tricky strategy for Bob to learn on its own, with Alice Behavioral Cloning (ABC), Bob eventually acquires the skills for solving such complex tasks proposed by Alice.
Novel Goals |
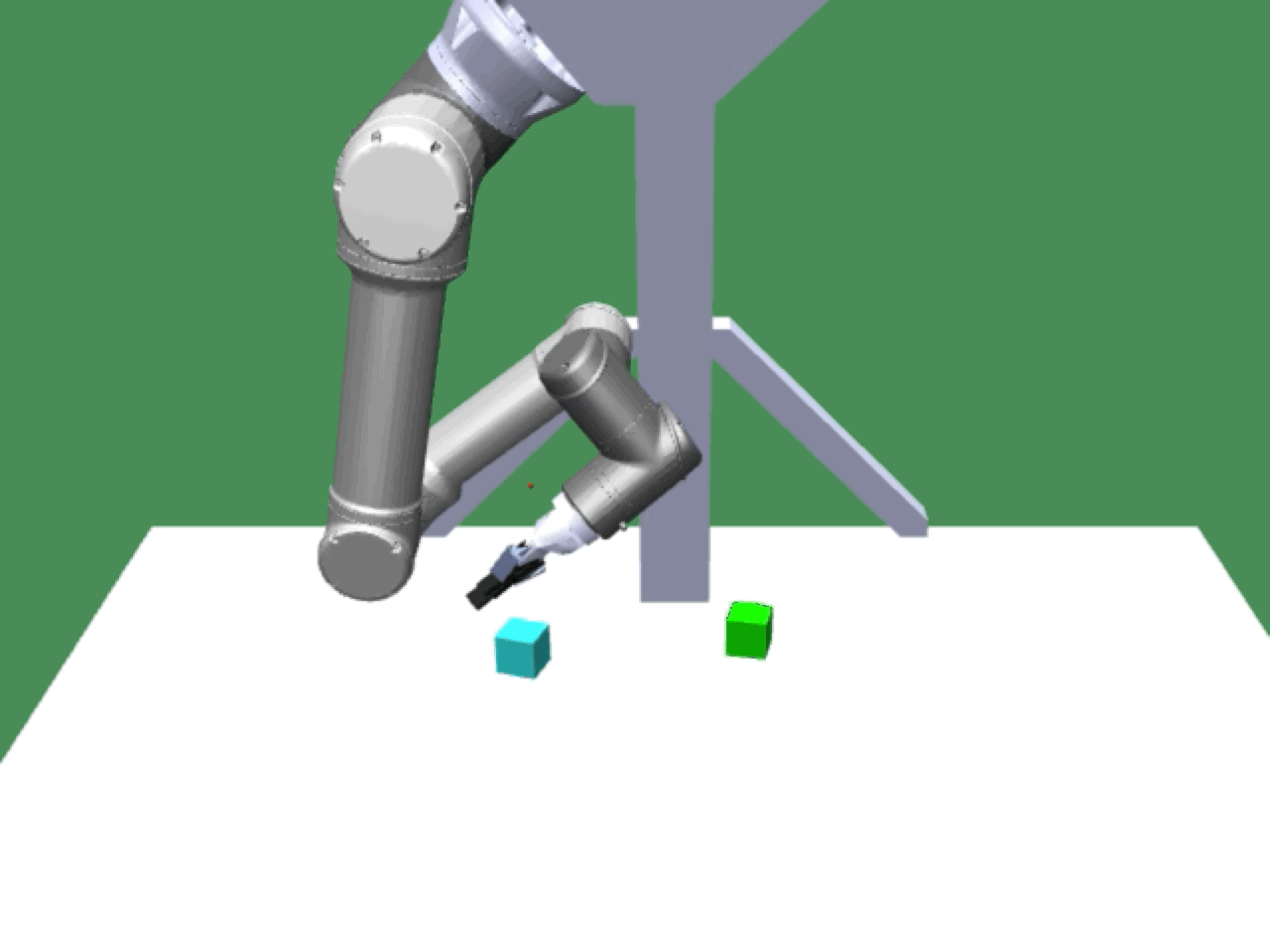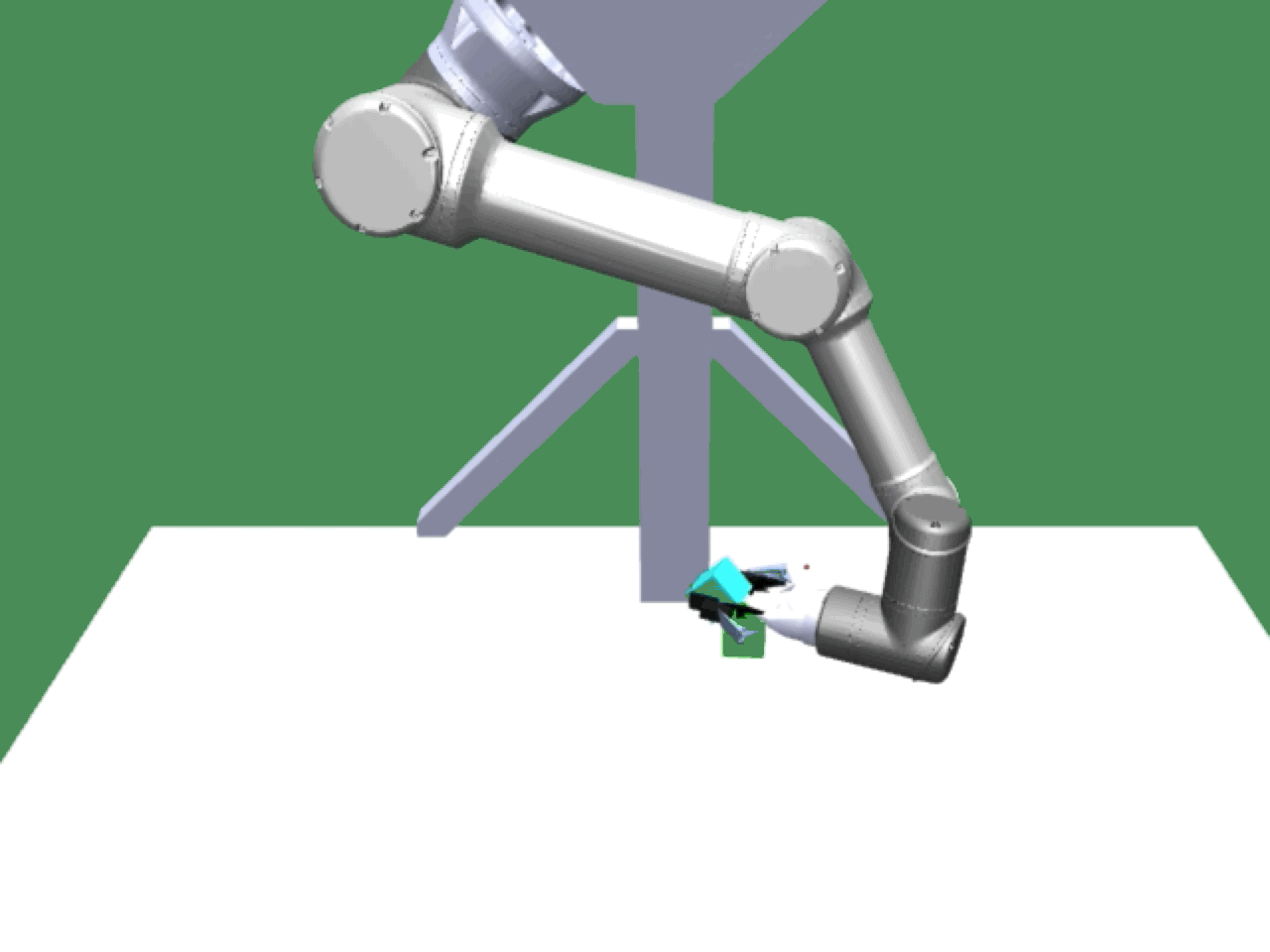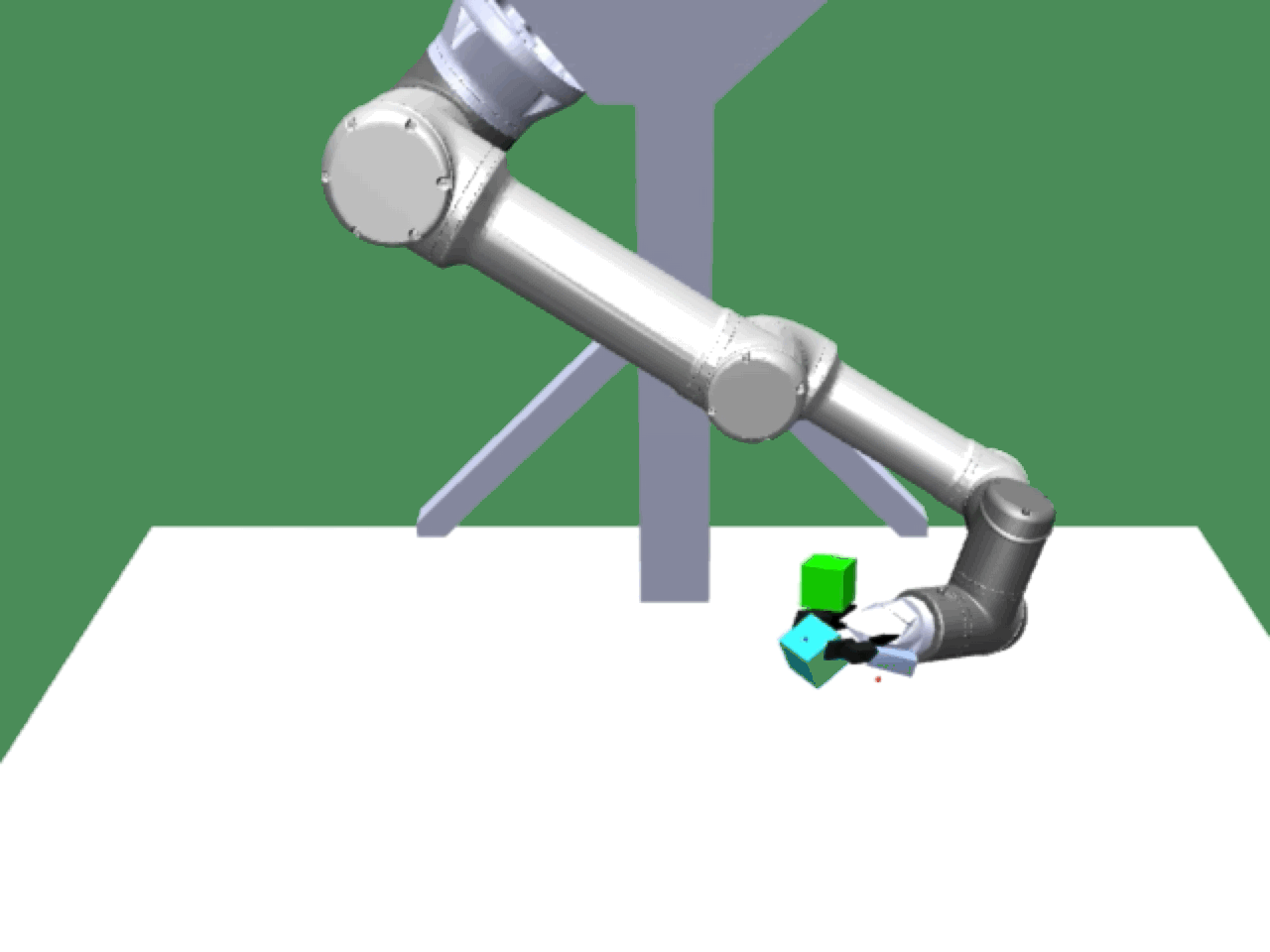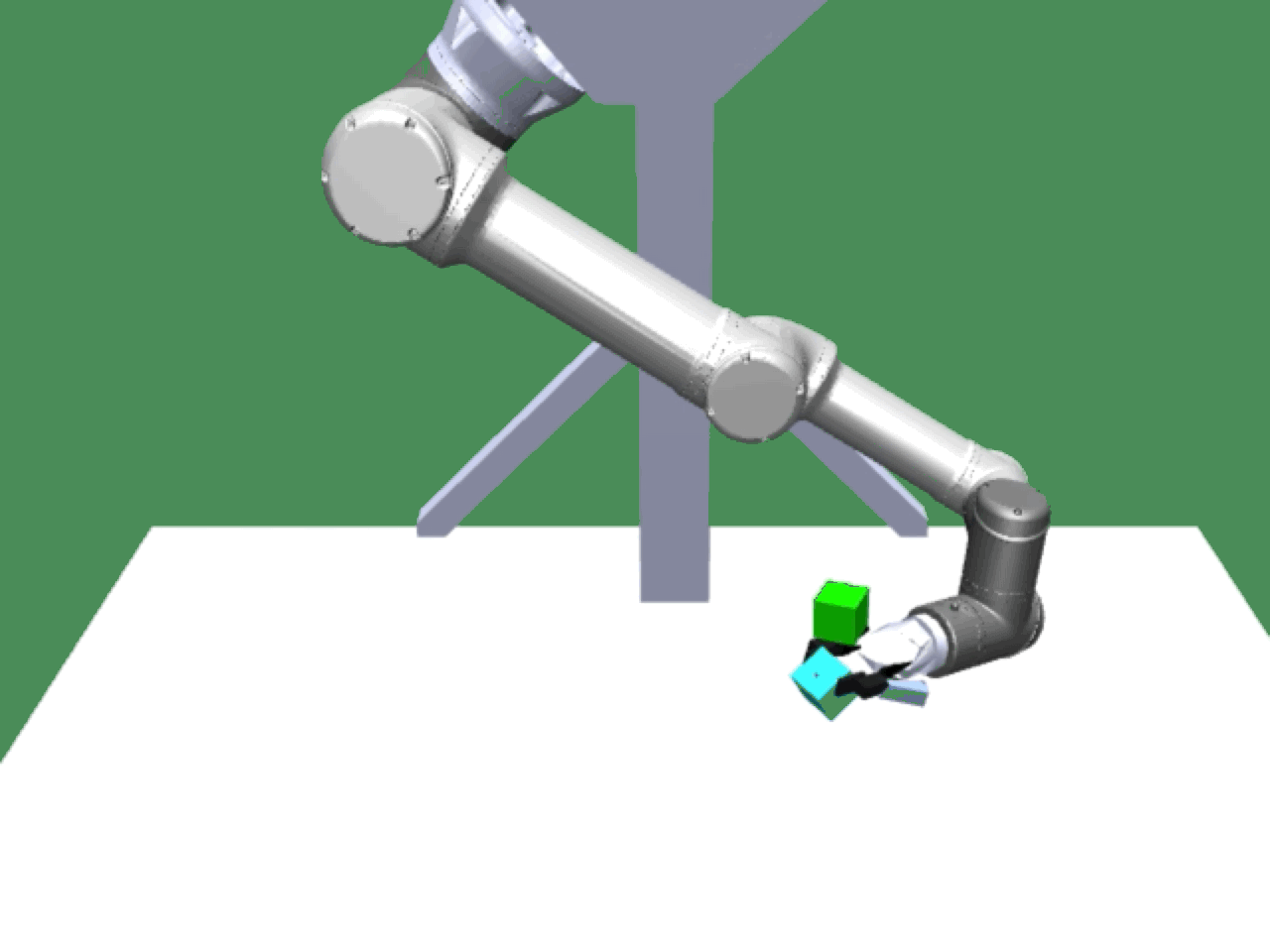 |
 |
 |
Novel Solutions |
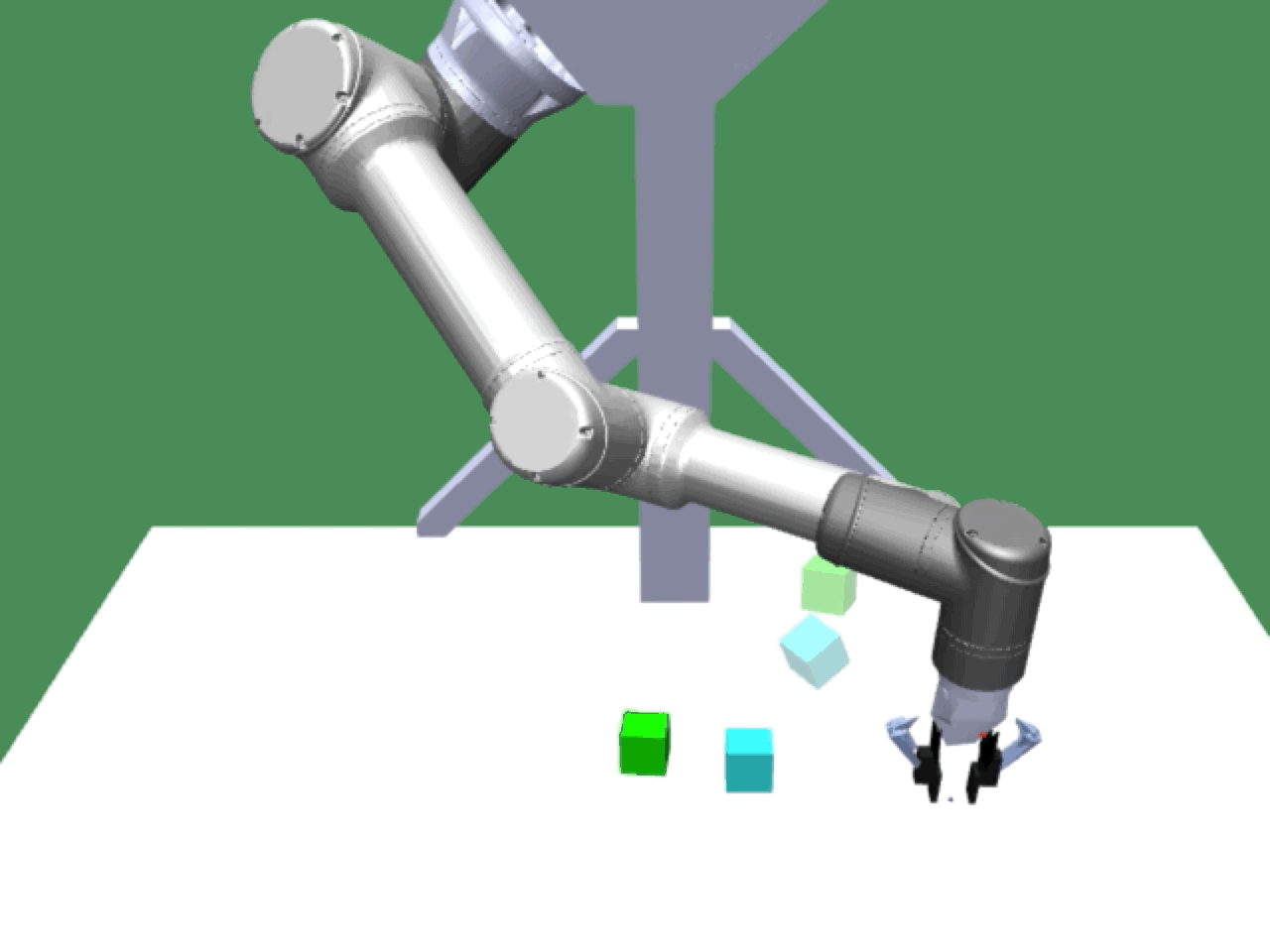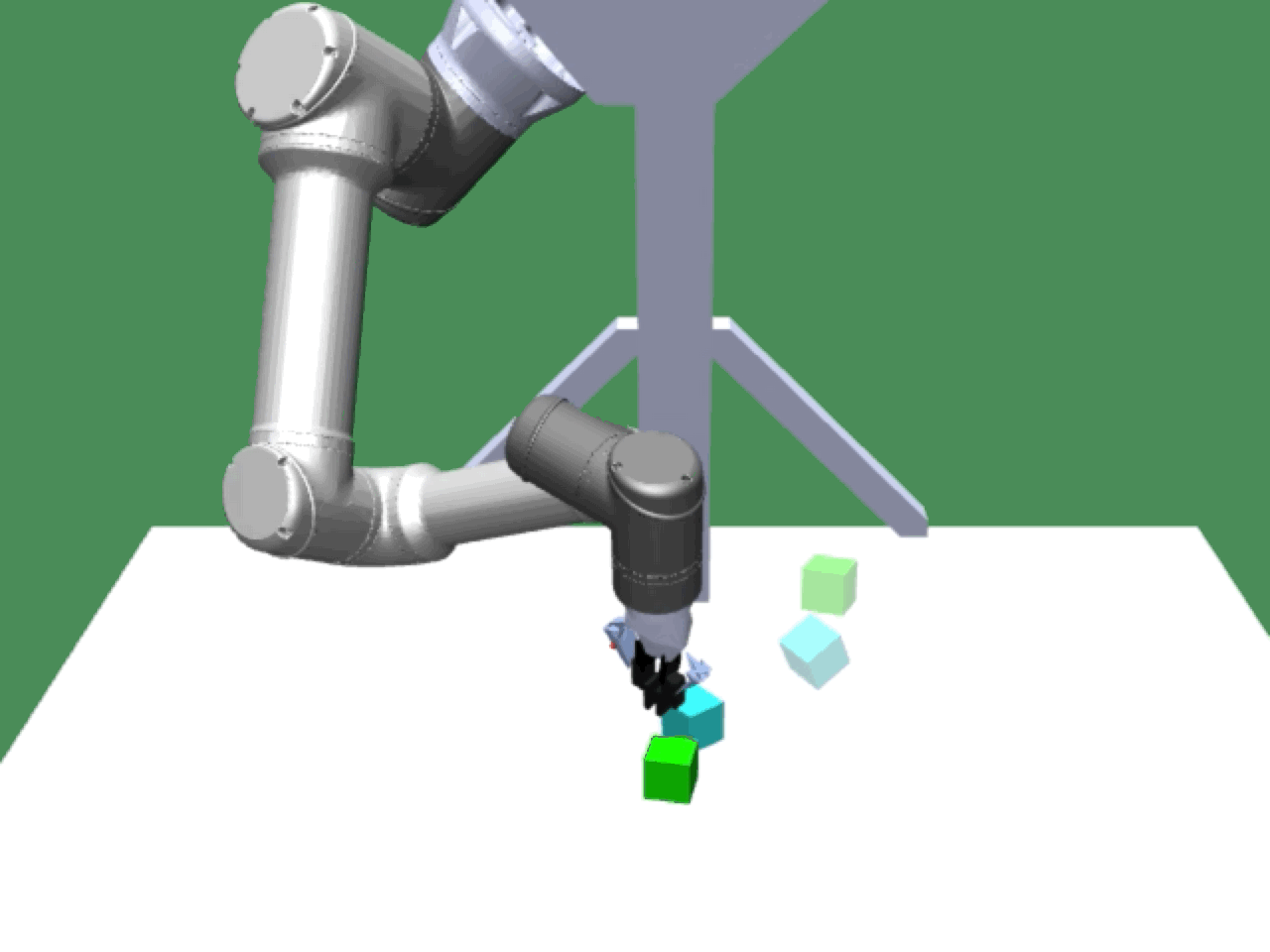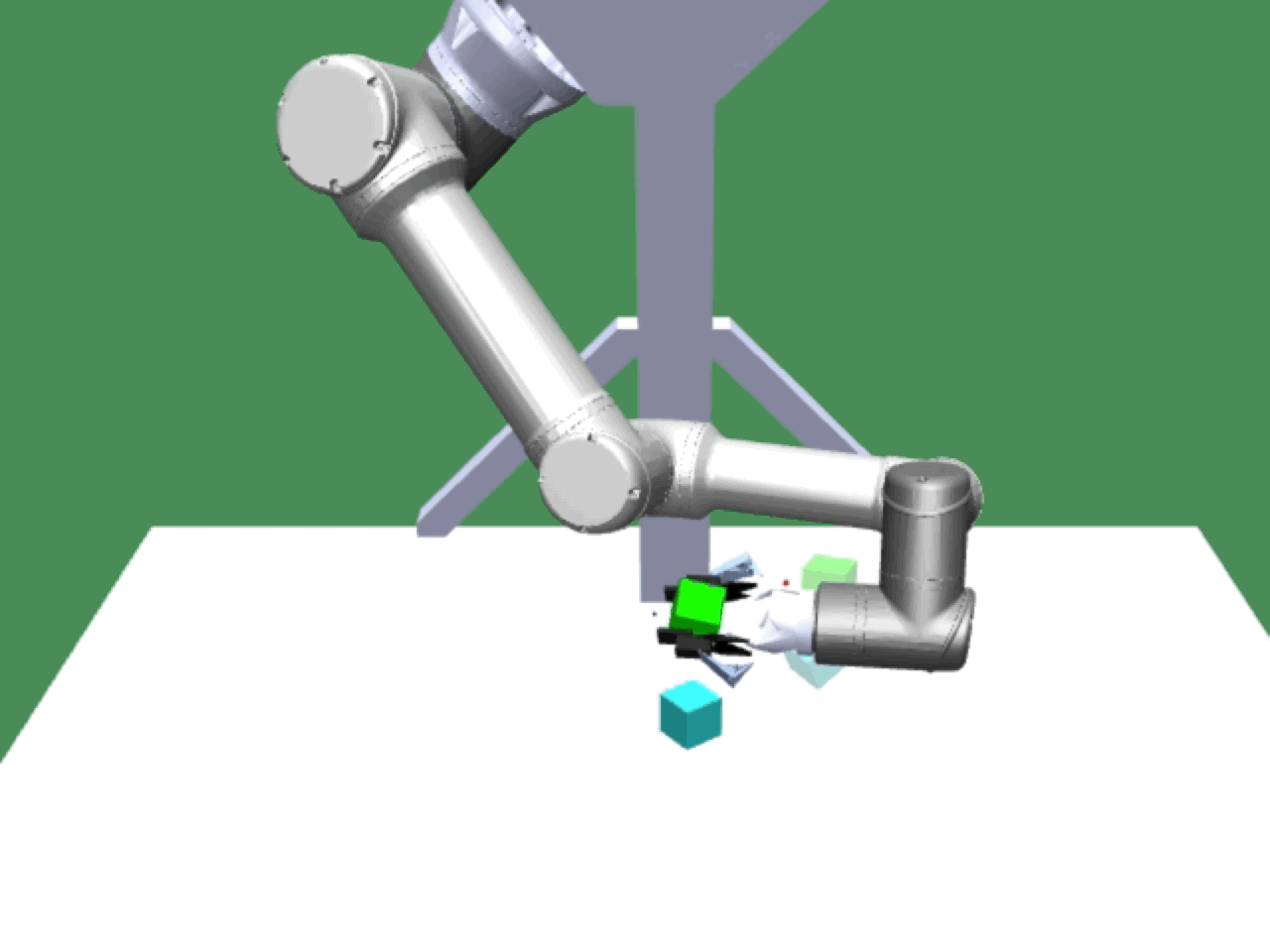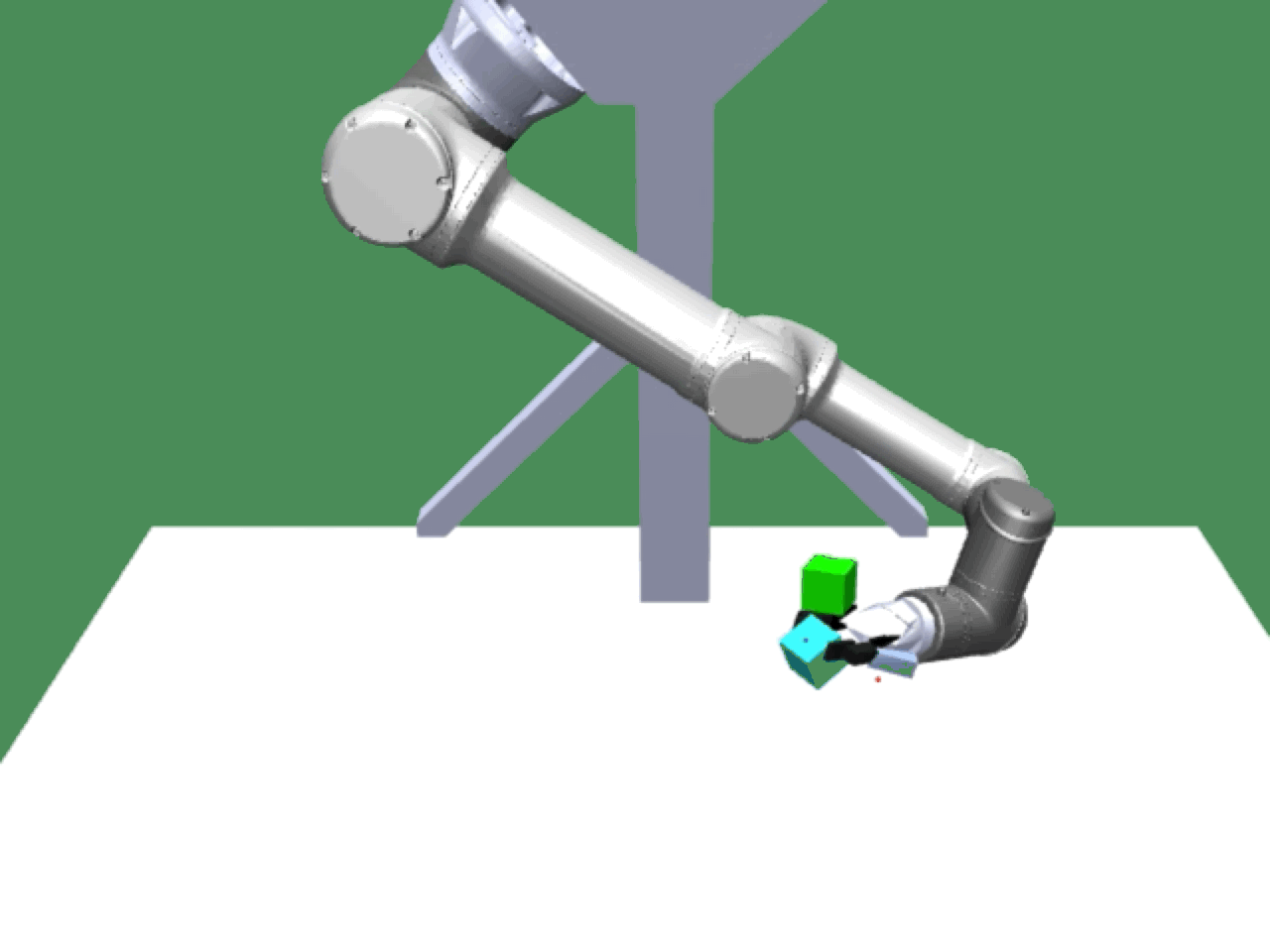 |
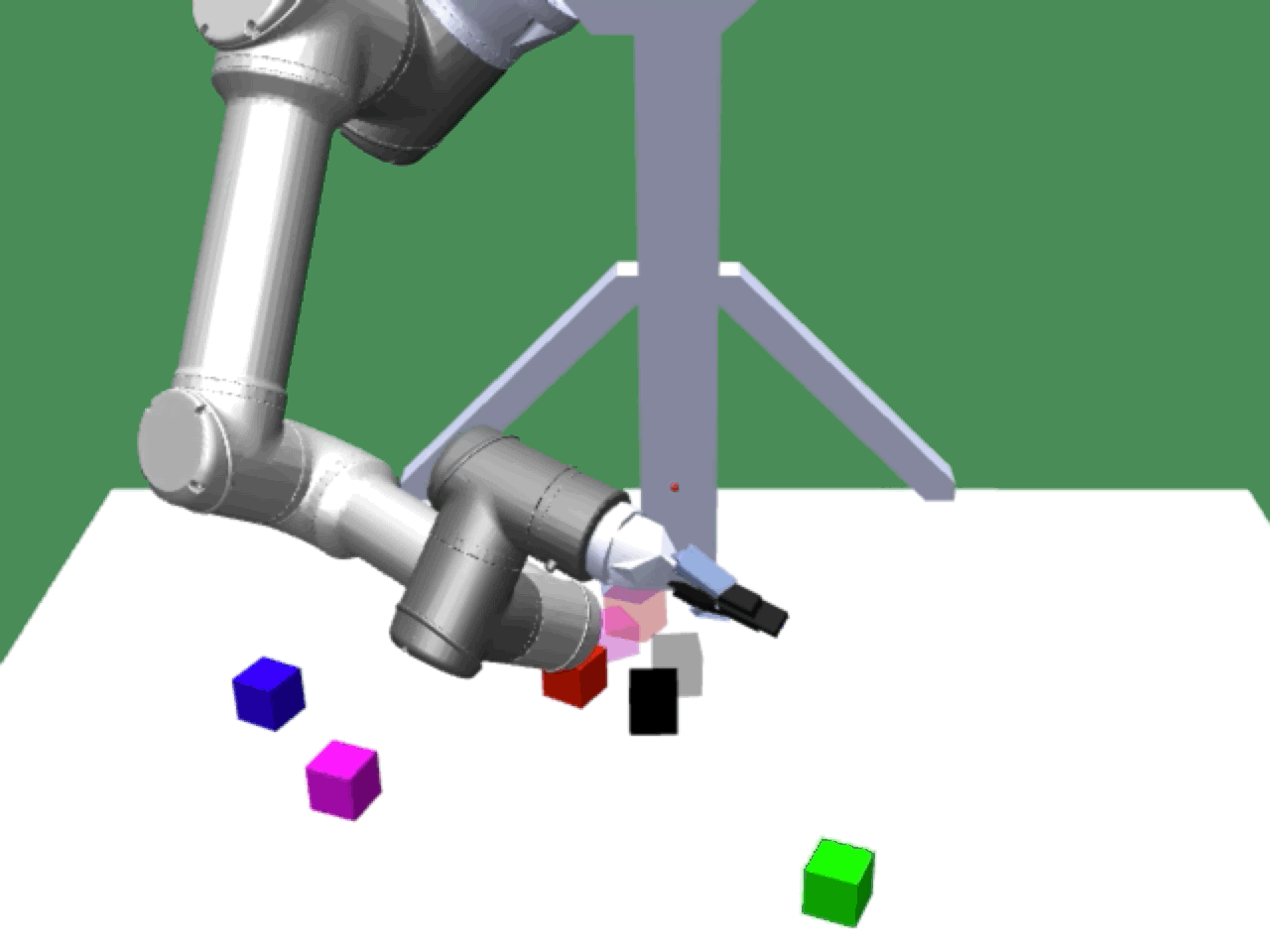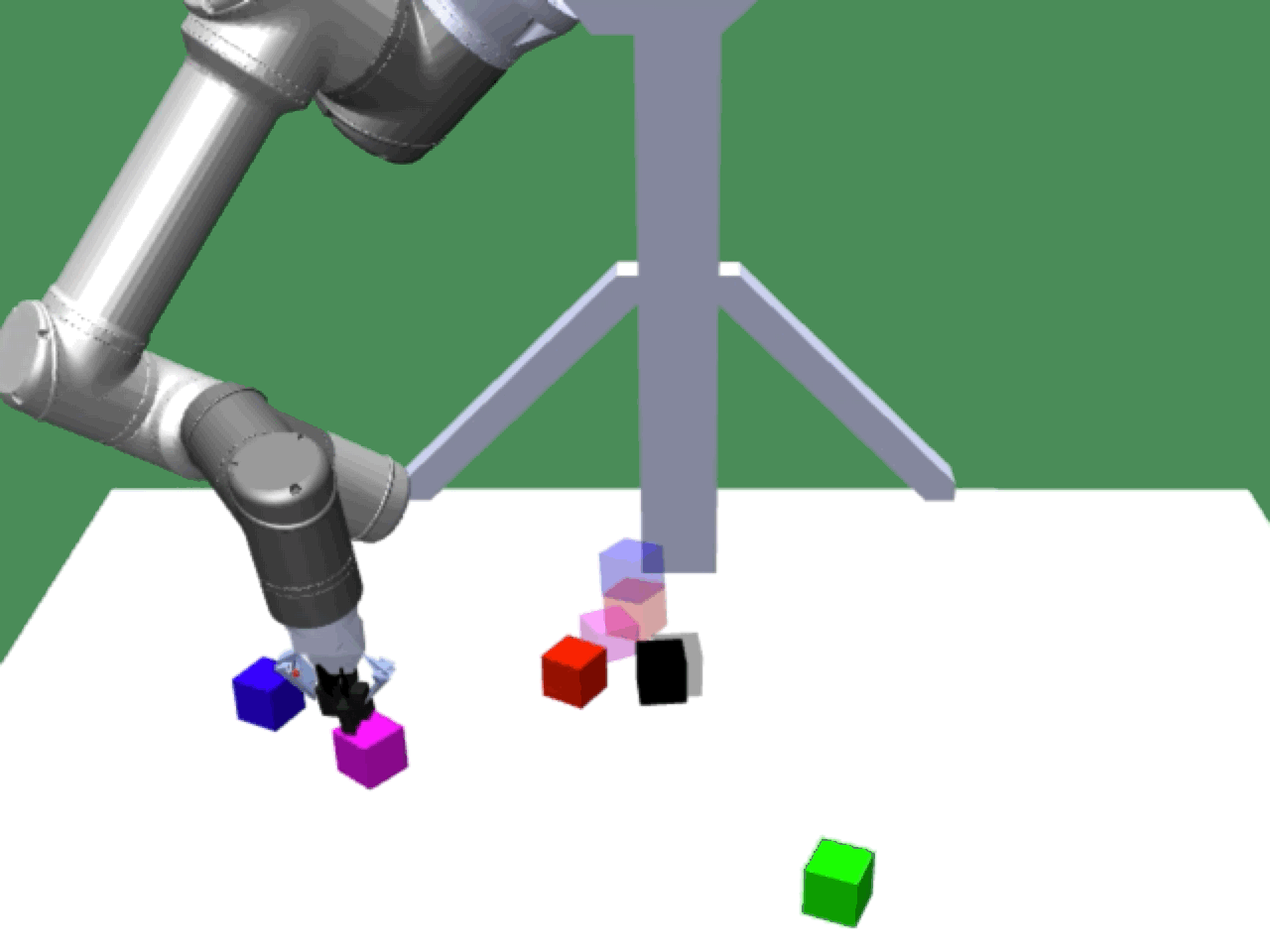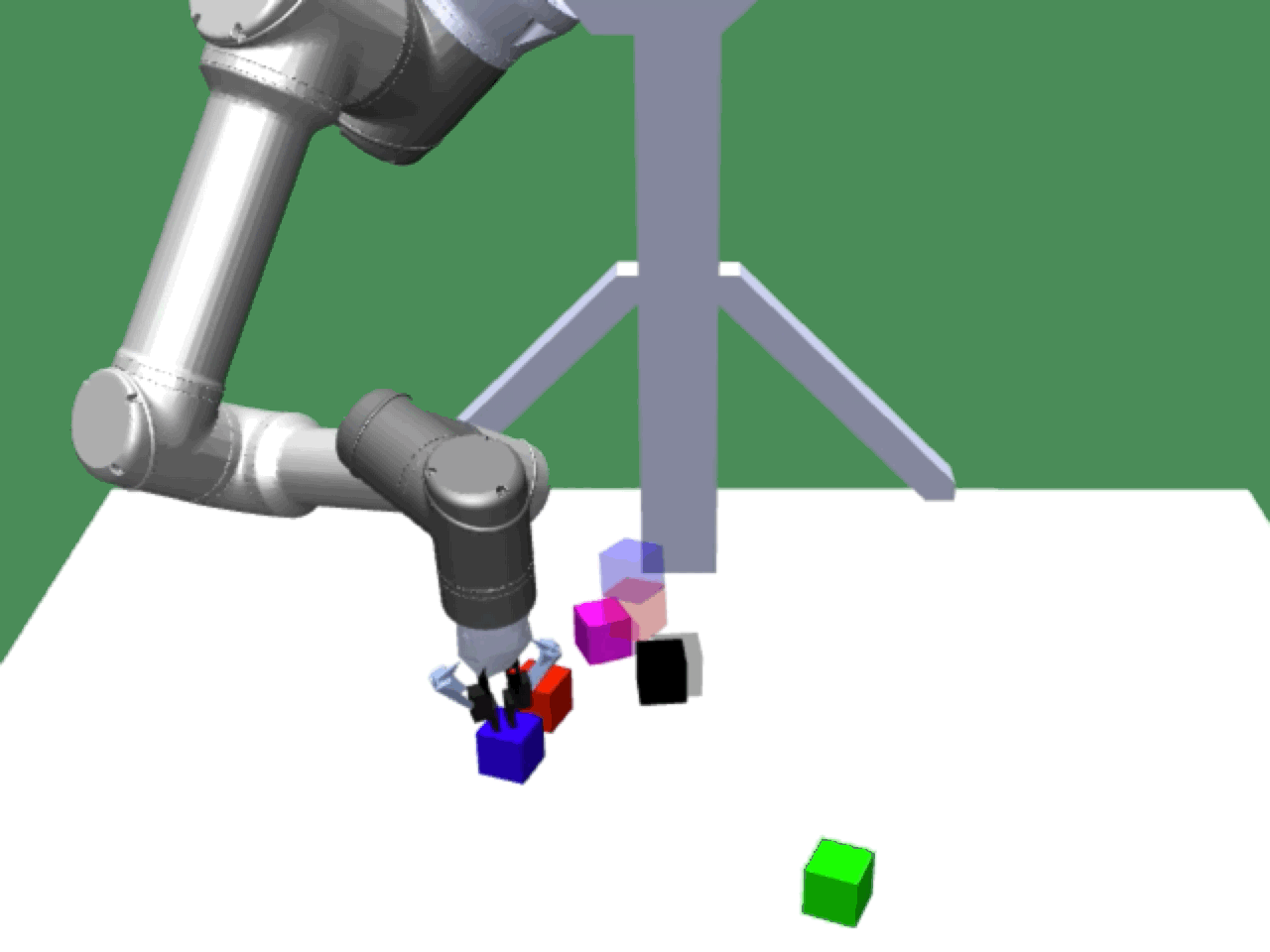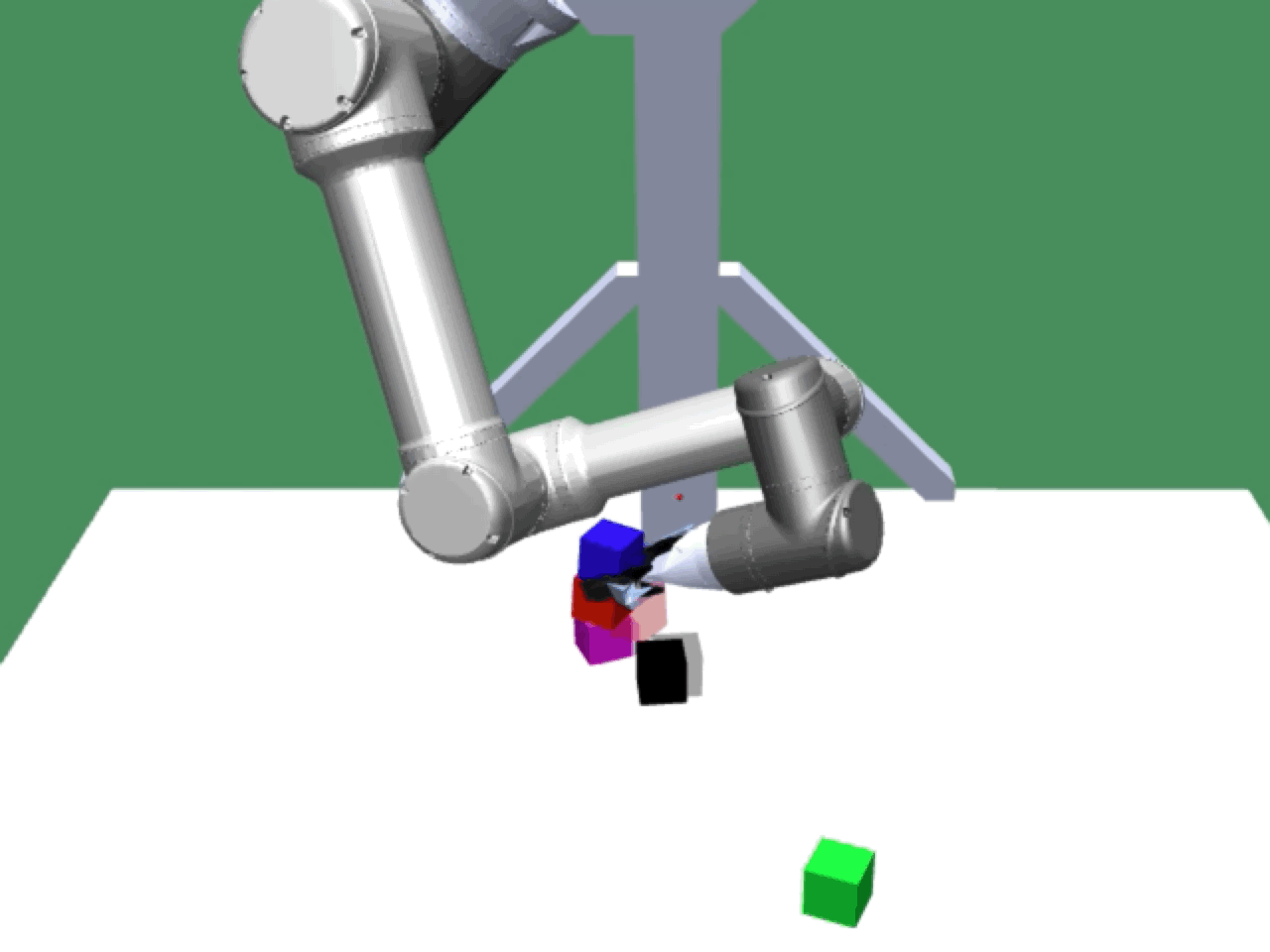 |
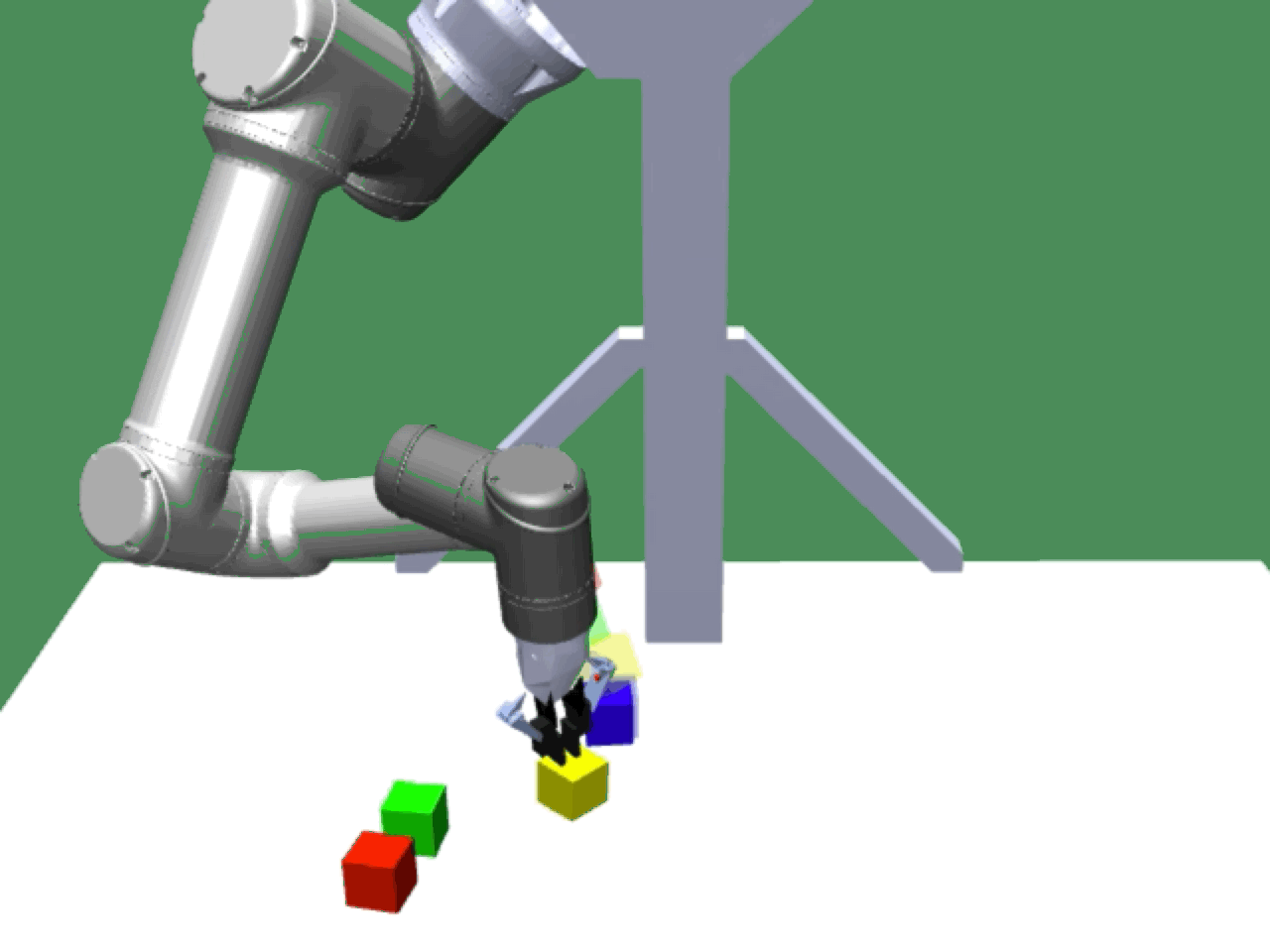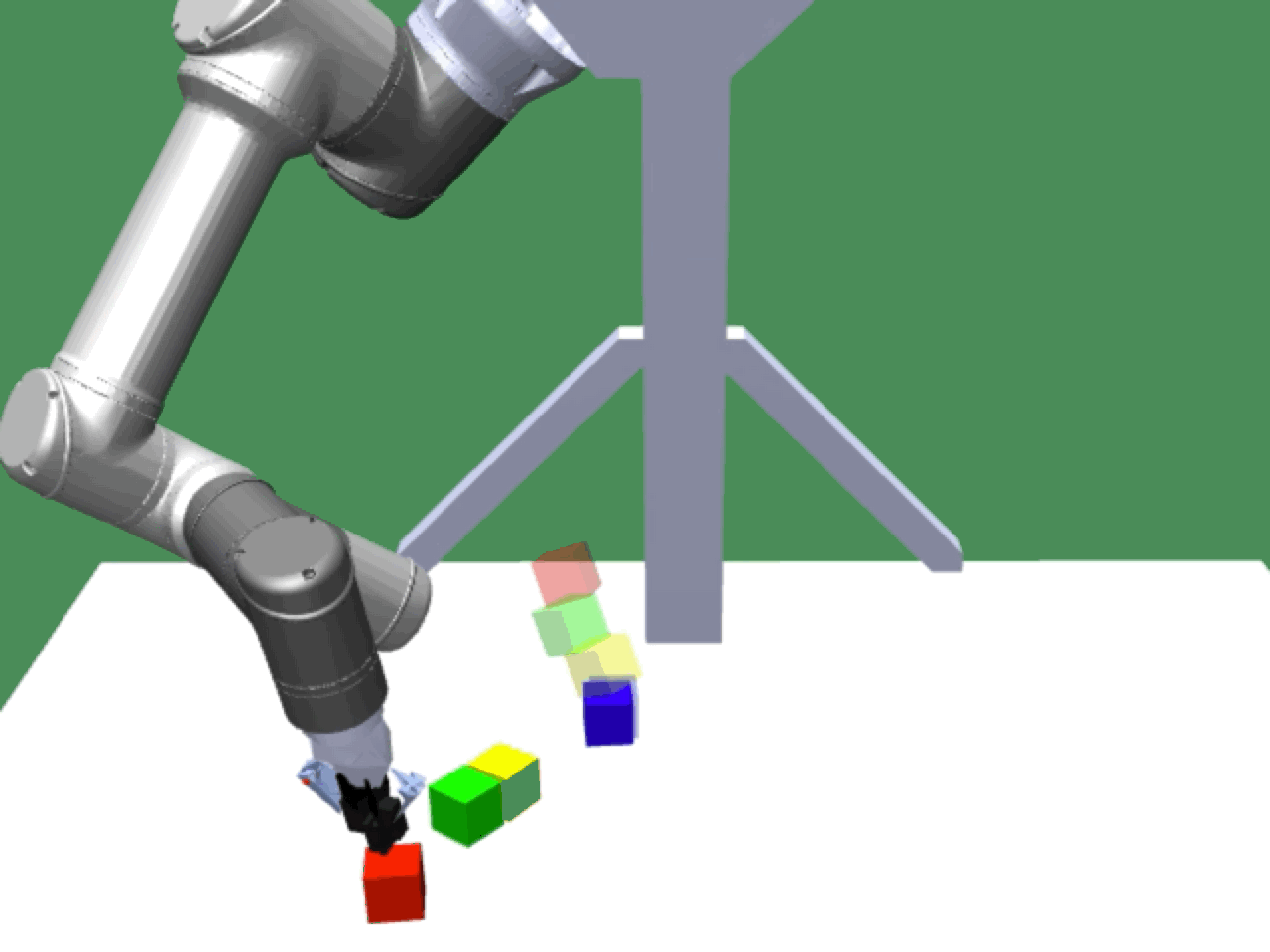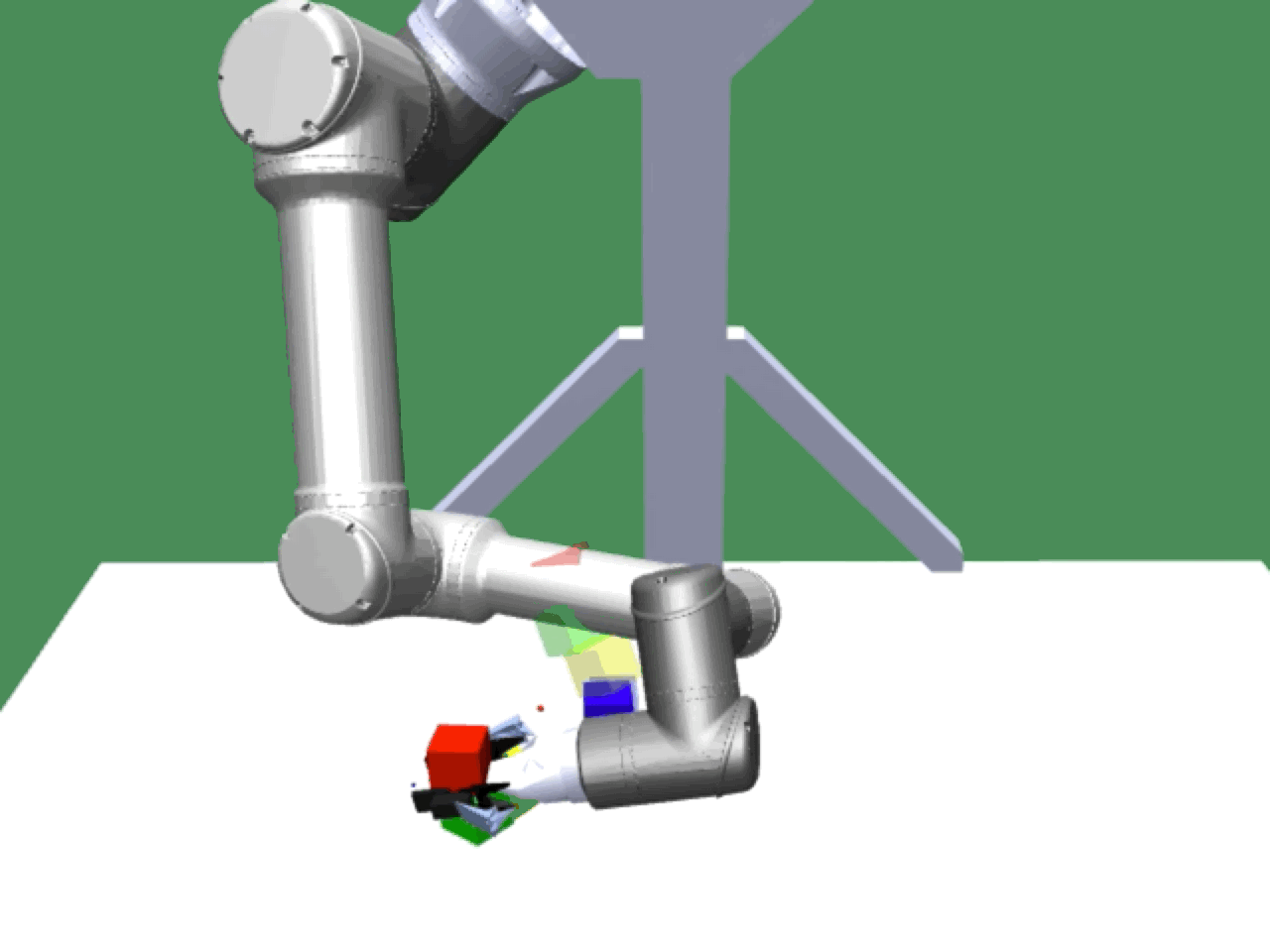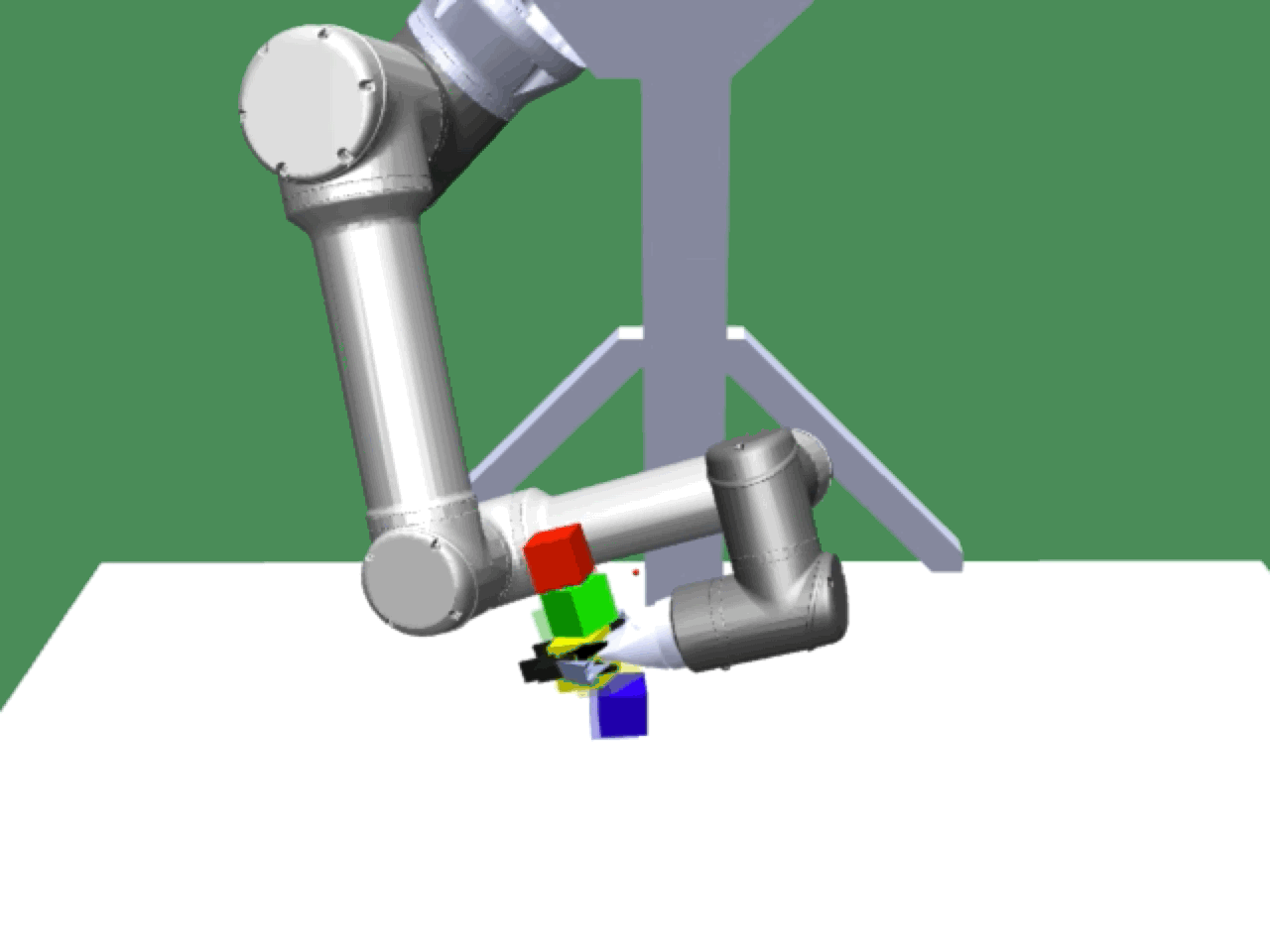 |
Complex manipulation skills can emerge from asymmetric self-play. The policy learns to exploit the environment dynamics (e.g. friction) to change object state and use complex arm movement to effectively grasp and rotate objects.
Emergent Complex Skills |
 |
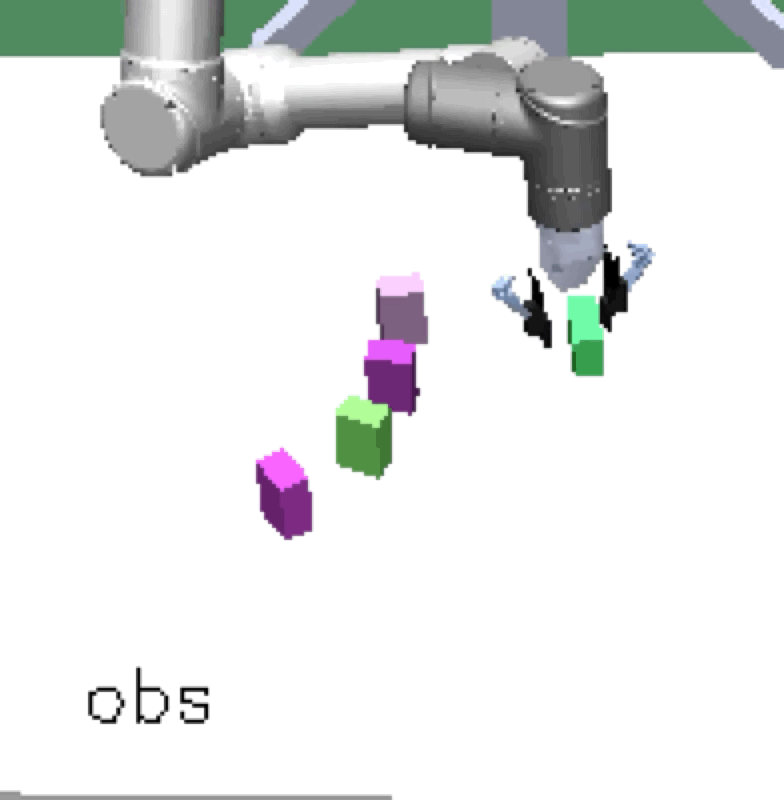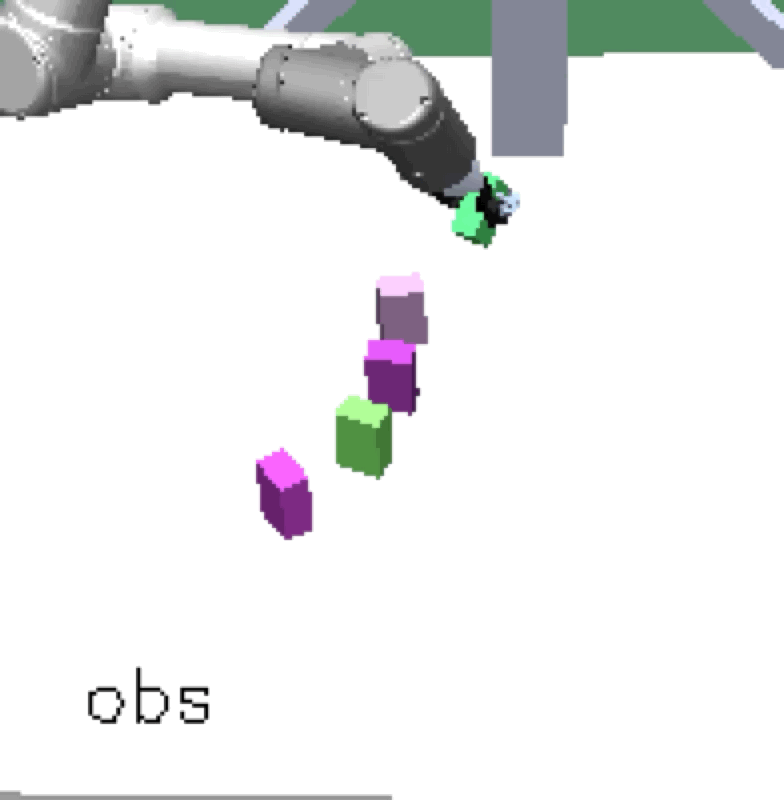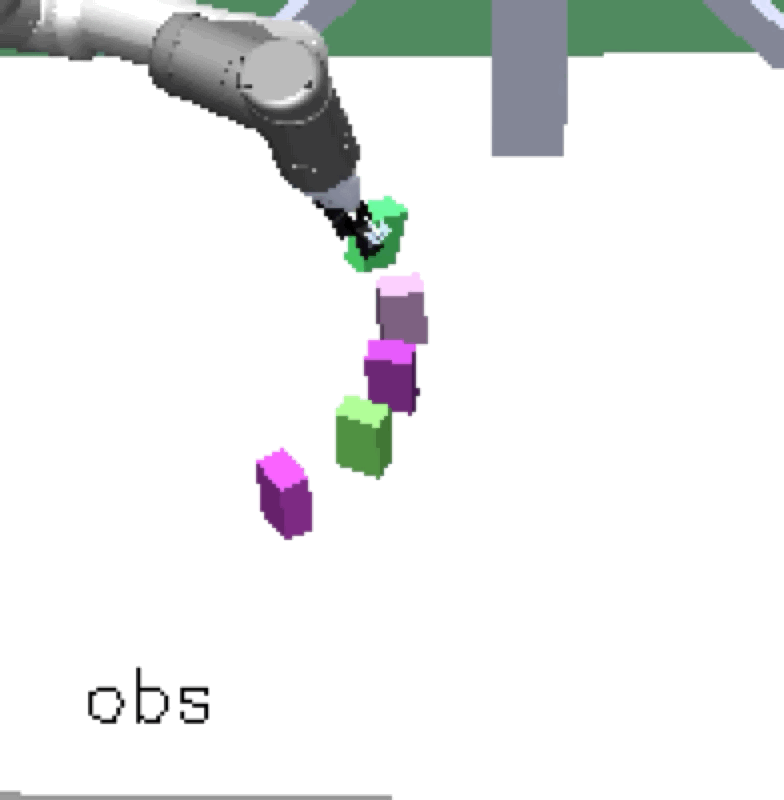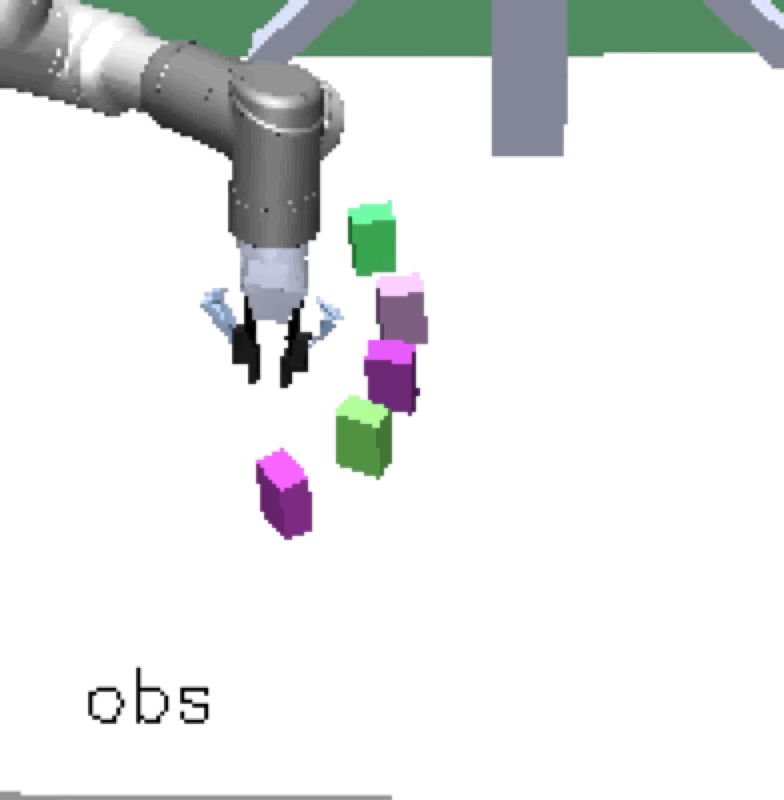 |
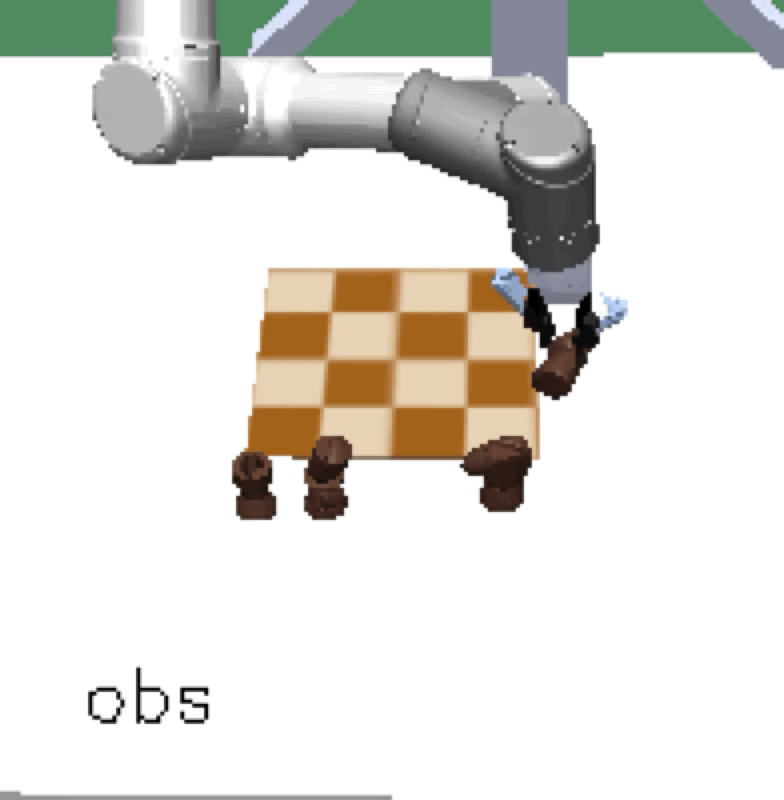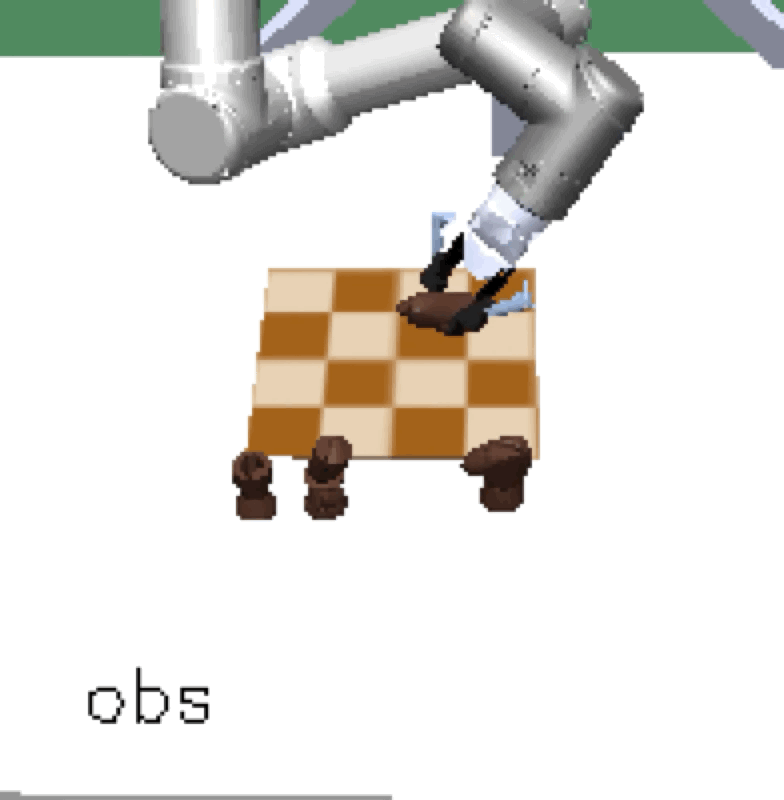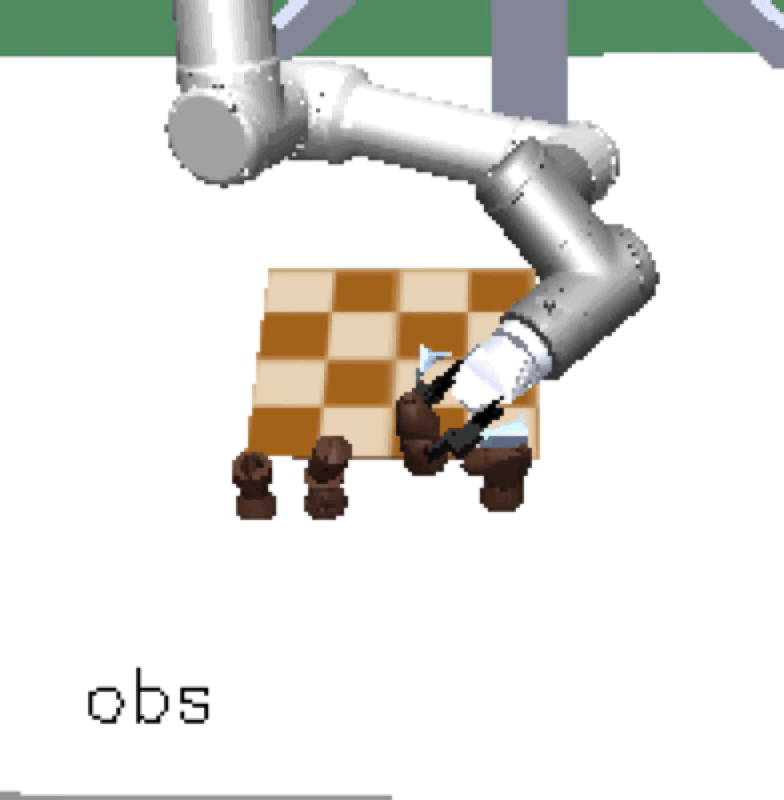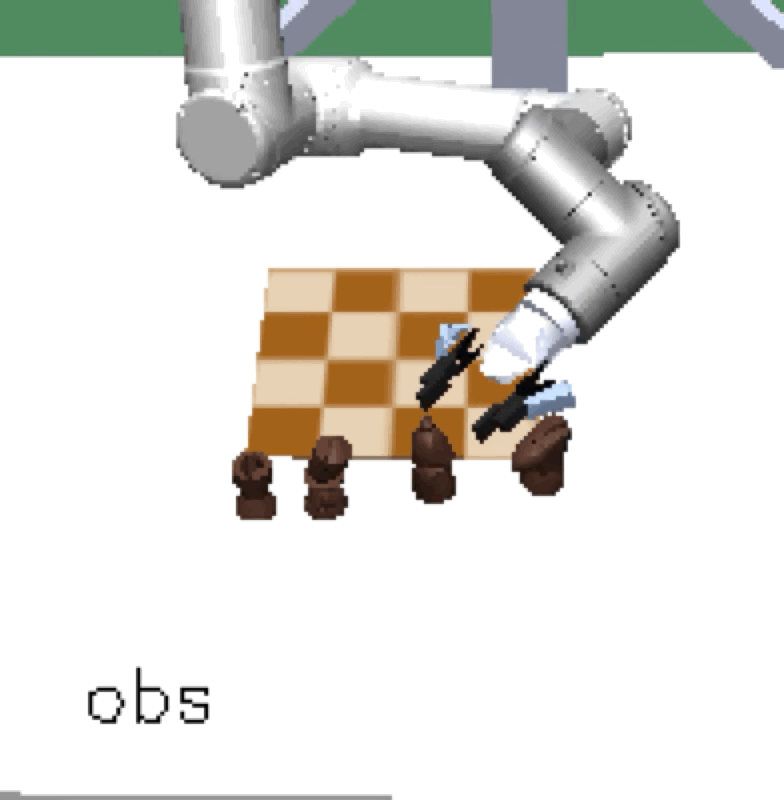 |